在 LlamaIndex🦙 框架中,提供了豐富的 Query 與 Chat Engine 功能,使得我們能更靈活地處理資料的檢索和互動。透過這些引擎使用者可以更精確地從資料庫中提取所需的資訊,並利用大語言模型(LLM)生成精確的回答。接下來,我們將深入探討各種 Query Engines 和 Chat Engines 的功能和參數設置,並解析不同模式下的應用範例,幫助你更好地掌握這些工具的應用。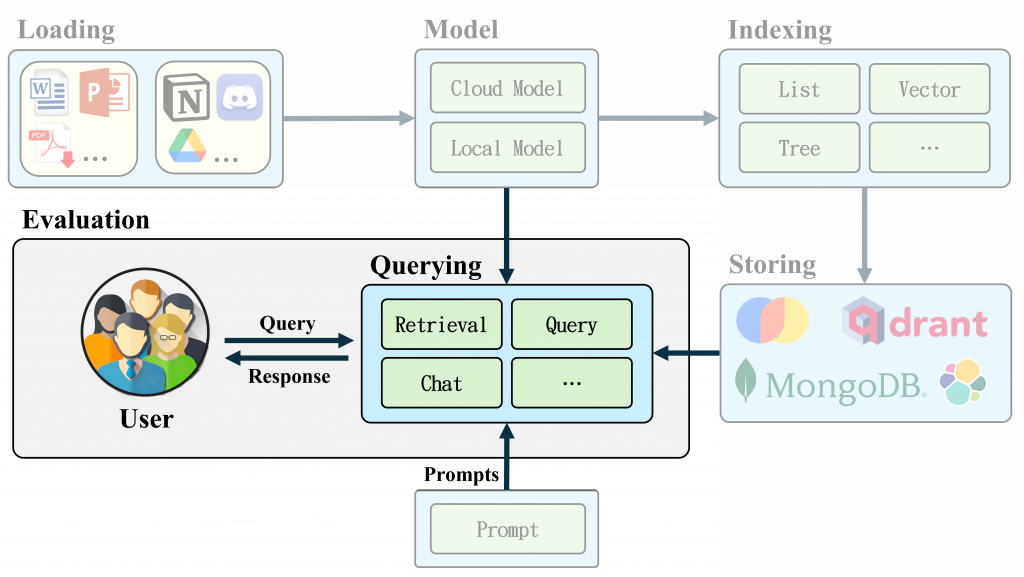
各 Engine 中使用的 LLM、Embedding、Chunk_Size等設定,可以參考此官方文件,因為較為簡單就不多做介紹了。
提供一個數據問答的(QA)接口,透過 retrievers 回傳相關文檔後利用 LLM 回答用戶查詢。LlamaIndex 集成了各項功能,如果想了解背後 LLM 運作流程可以在 Code 加上以下程式,會自動印出執行的 Prompt 內容,透果此指令能更好理解以下講解的內容。
import llama_index.core
llama_index.core.set_global_handler("simple")
index.as_query_engine(
similarity_top_k=2,
response_mode="compect",
)
similarity_top_k:每次檢索最相關的 k 個 Node。
streaming:決定 LLM 回答方式。
response_mode:檢索 + LLM 回覆的執行流程。以下將詳細介紹各模式的差異:
(在符合 Token Limit 限制下),如超過 Token Limit 則執行多輪問答直至完成回覆。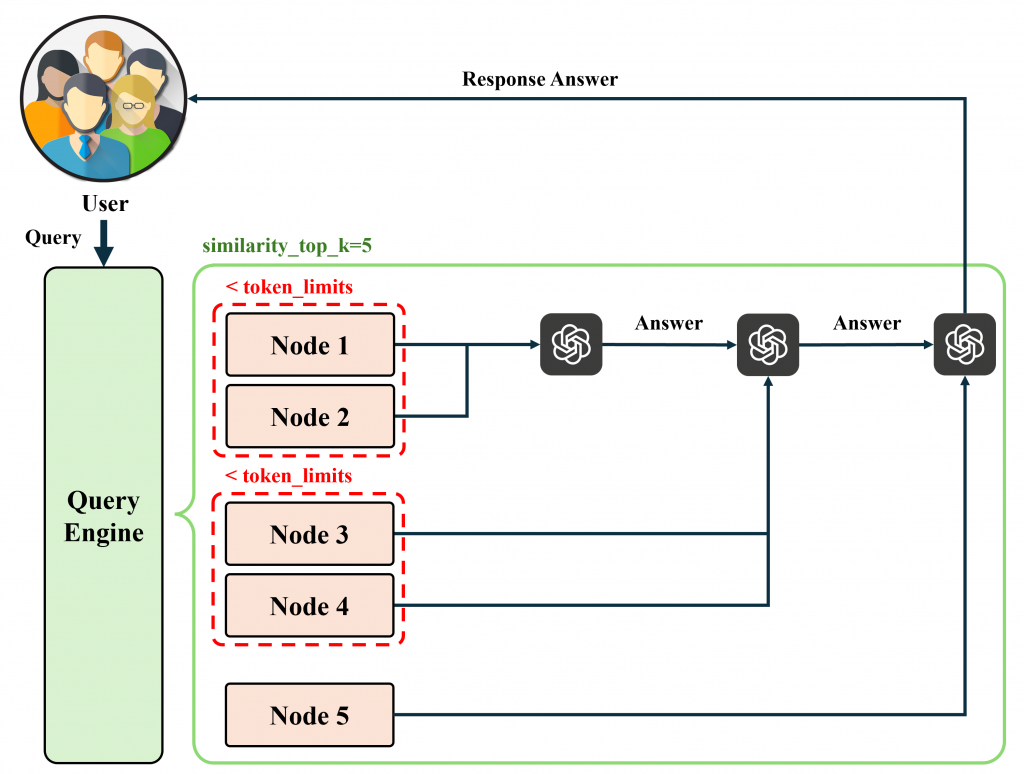
(如一個 Node 超過 Token Limit 會切割後分開發送),反覆此操作直至所有 Nodes 都被使用到。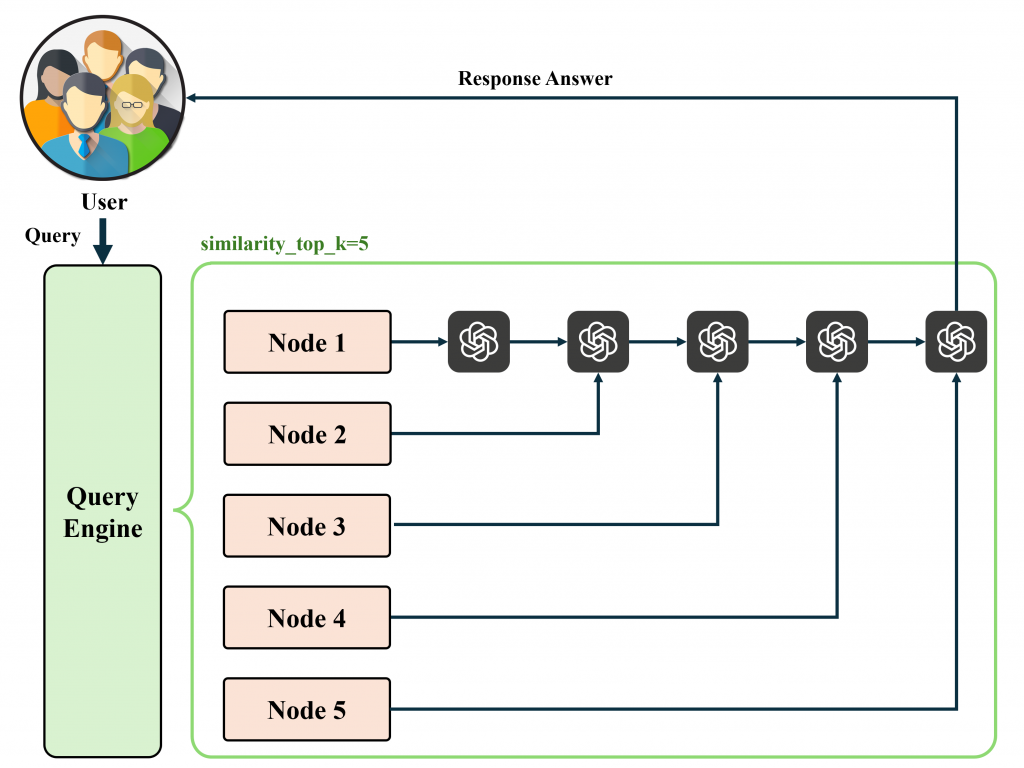
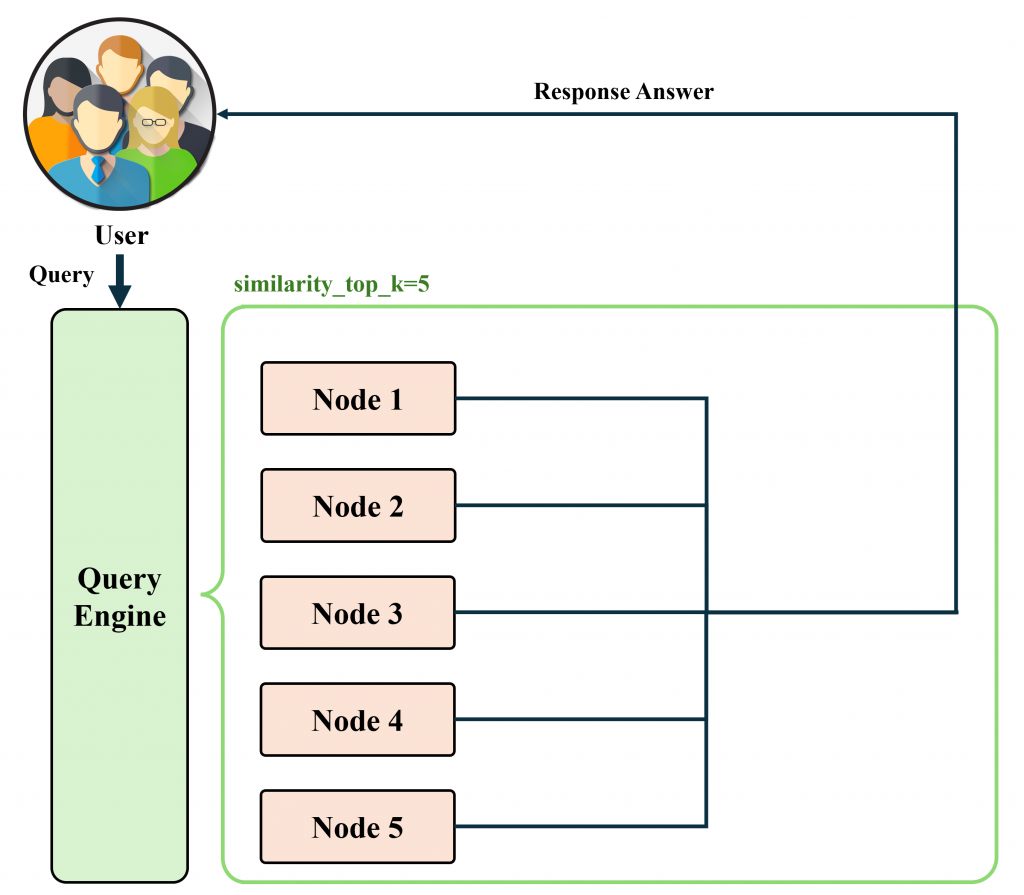
(適合快速摘要,但可能因截斷而遺失細節。),透果以下 Prompt 中 Relevant Content 範例可以看出差異。# Compact:
city: 台中
台中位於台灣中部,氣候溫暖,擁有台灣第三大城市的規模。它以文化氣息濃厚著稱,擁有豐富的藝術與文化活動,如國立台灣美術館、霧峰林家花園等。台中還是熱門的觀光景點之一,尤其以彩虹眷村和高美濕地最為著名。此外,台中市還以舒適的生活環境和悠閒的生活步調著稱,常被視為居住和發展的理想城市。台中的夜市文化也相當發達,逢甲夜市是其中最具代表性的夜市之一,吸引了無數美食愛好者前來品嚐台灣各地的美食
city: 台北
台北是台灣的首都,也是台灣政治、經濟、文化和交通的中心。這座城市充滿了活力與多元文化,結合了現代與傳統的魅力。台北擁有世界知名的地標——台北101,它曾是全球最高的摩天大樓,並且是購物和觀光的熱門地點。此外,台北還有許多文化和歷史景點,如故宮博物院、龍山寺和中正紀念堂,吸引了大量國內外遊客。台北市內交通便捷,捷運系統發達,是探索這座都市的絕佳方式。這裡也是台灣美食的集中地,夜市文化如士林夜市、饒河街夜市更是不可錯過的體驗之一。
# simple_summarize:
['city: 台中\n\n台中位於台灣中部,氣候溫暖,擁有台灣第三大城市的規模。它以文化氣息濃厚著稱,擁有豐富的藝術與文化活動,如國立台灣美術館、霧峰林家花園等。台中還是熱門的觀光景點之一,尤其以彩虹眷村和高美濕地最為著名。此外,台中市還以舒適的生活環境和悠閒的生活步調著稱,常被視為居住和發展的理想城市。台中的夜市文化也相當發達,逢甲夜市是其中最具代表性的夜市之一,吸引了無數美食愛好者前來品嚐台灣各地的美食\ncity: 台北\n\n台北是台灣的首都,也是台灣政治、經濟、文化和交通的中心。這座城市充滿了活力與多元文化,結合了現代與傳統的魅力。台北擁有世界知名的地標——台北101,它曾是全球最高的摩天大樓,並且是購物和觀光的熱門地點。此外,台北還有許多文化和歷史景點,如故宮博物院、龍山寺和中正紀念堂,吸引了大量國內外遊客。台北市內交通便捷,捷運系統發達,是探索這座都市的絕佳方式。這裡也是台灣美食的集中地,夜市文化如士林夜市、饒河街夜市更是不可錯過的體驗之一。']
accumulate:針對每個 Node 生成出一個答案,並將回應累積到一個陣列中。最終會返回所有回應的字串集合。(適合在需要對每個段落分別執行相同查詢的情況下使用。)
compact_accumulate:compact + accumulate 的綜合體,會「壓縮」每個 LLM 提示,然後對每個段落分別執行相同查詢。
text_qa_template、refine_template:更改 Prompt 內容。
node_postprocessors:用於過濾 Nodes 內容,如相似度閾值。
# Import Module
# Create documents
...
# Set Parameter
...
# Embedding
index = VectorStoreIndex.from_documents(documents)
# Create Query Engine
query_engine = index.as_query_engine(
response_mode="compect",
similarity_top_k=2
)
response = query_engine.query("Your Query")
# Stream Response
query_engine = index.as_query_engine(streaming=True)
streaming_response = query_engine.query("Your Query")
streaming_response.print_response_stream()
LlamaIndex 提供一個數據對話的(Chat)接口,透過 retrievers 回傳相關文檔後利用 LLM 搭配歷史紀錄回答用戶查詢。LlamaIndex 集成了各項功能,如果想了解背後 LLM 運作流程可以在 Code 加上以下程式,會自動印出執行的 Prompt 內容,透果此指令能更好理解以下講解的內容。
import llama_index.core
llama_index.core.set_global_handler("simple")
best:將查詢引擎變成一個工具,可以與資料代理(Data Agent)配合使用,具體取決於 LLM 的支援情況。資料代理通常使用 OpenAI 的函數呼叫 API,如 GPT-3.5-turbo 或 GPT-4,並利用 ReAct 或 OpenAI 模式來執行。
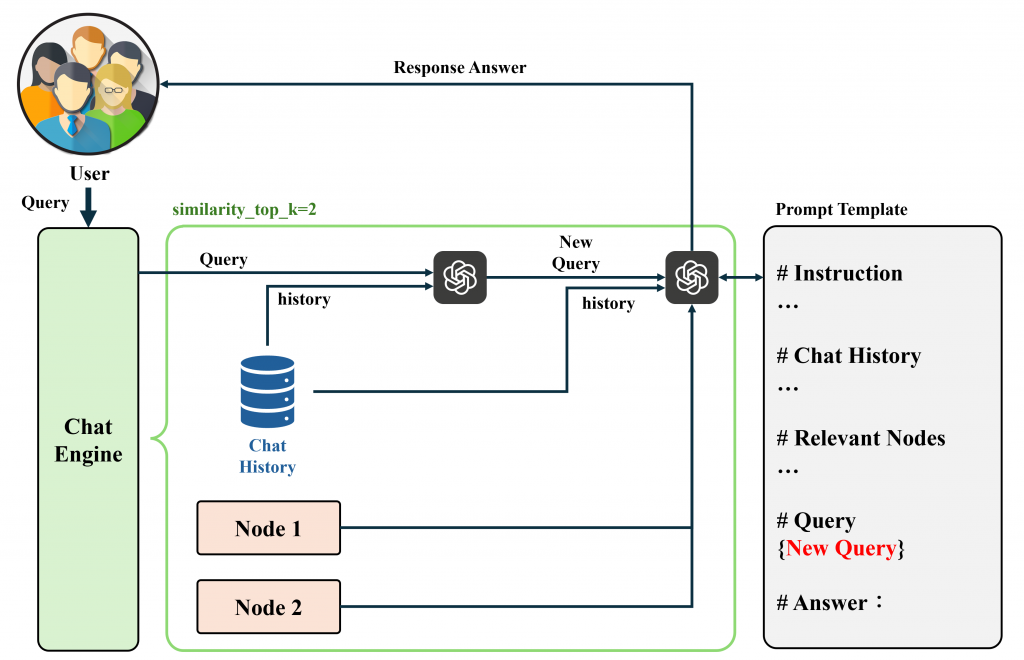
react:與 best 模式相同,使用了 Data Agent 並透過 ReAct 方法實現。簡單來說就是當用戶輸入查詢時,LLM 會先透過歷史資料判斷是否需要執行 Agent,如果歷史資料內容具有查詢的答案,則會直接回覆解答。
openai:與 best 模式相同,使用 Data Agent 並依賴 OpenAI Agent 方法。
condense_question:透過歷史聊天紀錄+使用者查詢產生一個新的查詢語句。結合相關 Nodes 和 新查詢語句透過 LLM 生成回覆。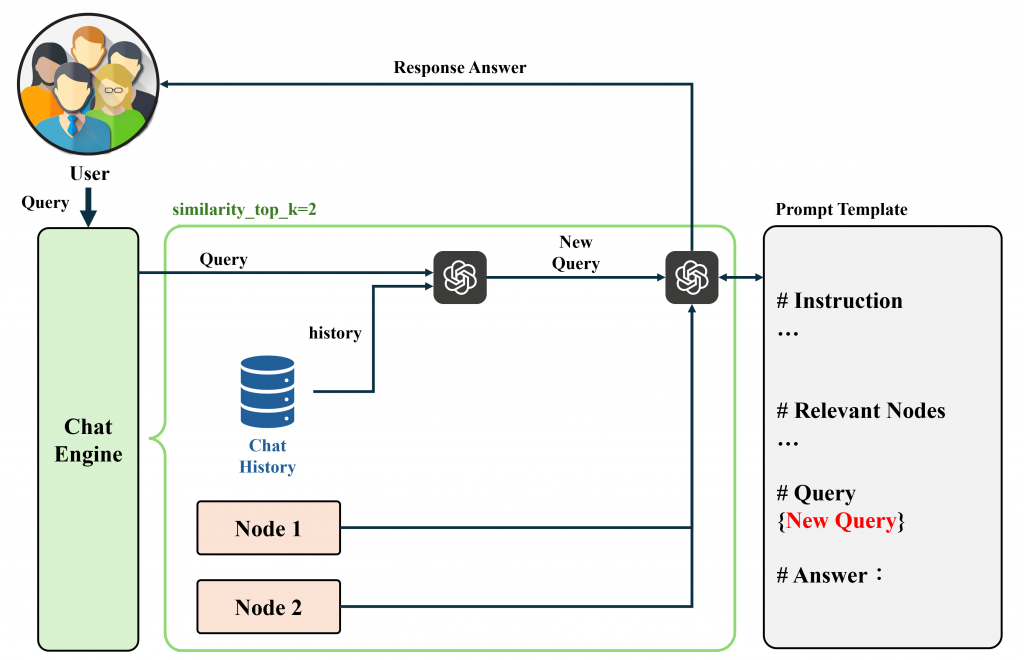
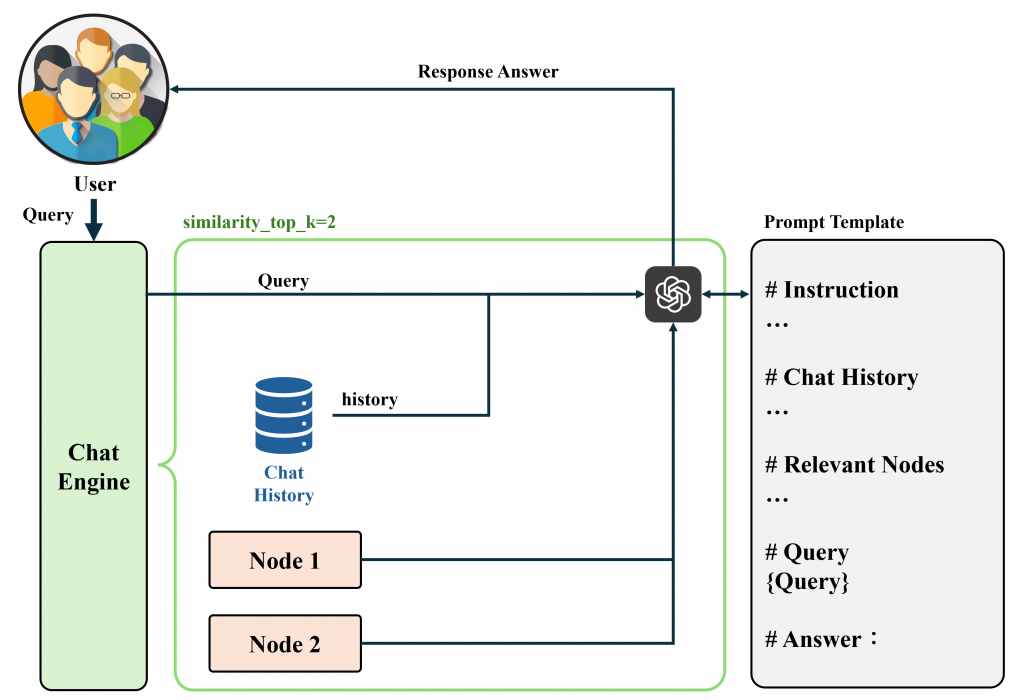
(跟直接使用 LLM 一模一樣。)。Routing 是一種透過 LLM 針對查詢進行選擇判斷的模組,解決了當我們同時有多個資料源時,系統無法決定要使用哪個引擎的問題。(簡單來說就是利用 Prompt 結合 description 和 Query 兩項資訊,並透過 LLM 進行判斷該使用的結果)。
筆者的經驗中,如果資料來源很相似,會遇到難以用文字區分各個引擎的內容,最終還是建議自定 Routing 會比 LLM 可靠性高更。
from llama_index.core.query_engine import RouterQueryEngine
from llama_index.core.selectors import PydanticSingleSelector
from llama_index.core.tools import QueryEngineTool
list_tool = QueryEngineTool.from_defaults(
query_engine=list_query_engine,
description="Useful for summarization questions related to the data source",
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=vector_query_engine,
description="Useful for retrieving specific context related to the data source",
)
query_engine = RouterQueryEngine(
selector=PydanticSingleSelector.from_defaults(),
query_engine_tools=[
list_tool,
vector_tool,
],
)
query_engine.query("<query>")
LlamaIndex 的 Query 和 Chat Engine 為資料檢索和對話提供了強大且多樣化的支持。在 Query Engine 中,從簡單的檢索 Node 到複雜的多輪查詢流程,使用者可以根據需求靈活選擇參數與模式,無論是要處理大規模資料的摘要,還是細緻到每個段落的深度解讀。 Chat Engine 則將歷史紀錄與即時查詢相結合,提供了多層次的回答模式,並可輔以資料代理(Data Agents)和 LLM 互動,使其不僅適合單次回答,更具備多輪對話的記憶與上下文理解能力。
透過這些功能,我們可以更精確地處理各種查詢與對話需求,從而提升應用的智能化程度與回應品質。無論是為了快速回應使用者查詢,還是進行深度對話,LlamaIndex 的靈活架構都能滿足各類場景的應用需求。

